Status: Tags: #cards/cmpt295/mp Links: Microprocessor
Microprocessor Pipeline Execution
Principles
- Start executing 1 instruction at each clock cycle
- Overlap different stages as different instructions are executing
- Higher throughput
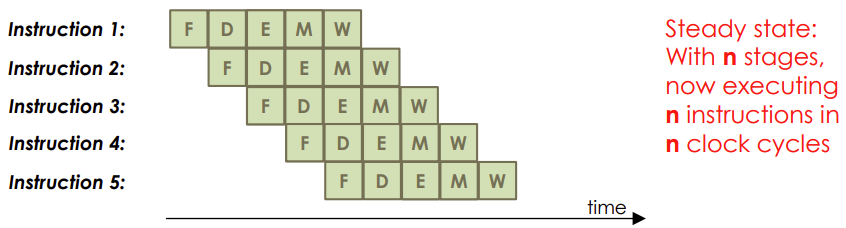
Stages
Assume each stage takes 80, register is 20
- Same as Microprocessor Staged Execution
- Latency (Cost per instruction)
- (400/5 ps + 20px)5 = 500ps
# blocks xlongest cycle` = latency
- CPU throughput
- 1 /
longest cycle= throughput - 5/500ps = 10 GIPS
- 1 /
- CPI: 5
- Clock cycle: 80 + 20ps = 100ps
Limitations
- Doubling number of stages would not double throughput
- Clock cycle would be limited by latency of the slowest stage
- Contains Pipeline Hazards
- Same register is used after the same step, so there may be overwriting complications
References:
Created:: 2022-04-03 17:18